Teaser
3D pose estimation on random videos from the internet using a single model for all the following categories.
We show 3D pose estimation on various deformable categories from the internet, including OpenAI's SORA videos. No camera information is required, allowing 3D-LFM to work out of the box on many of these categories, provided 2D landmarks are available (in any order or joint connectivity).
Unified 3D-LFM Model
A single model for 30+ object categories.


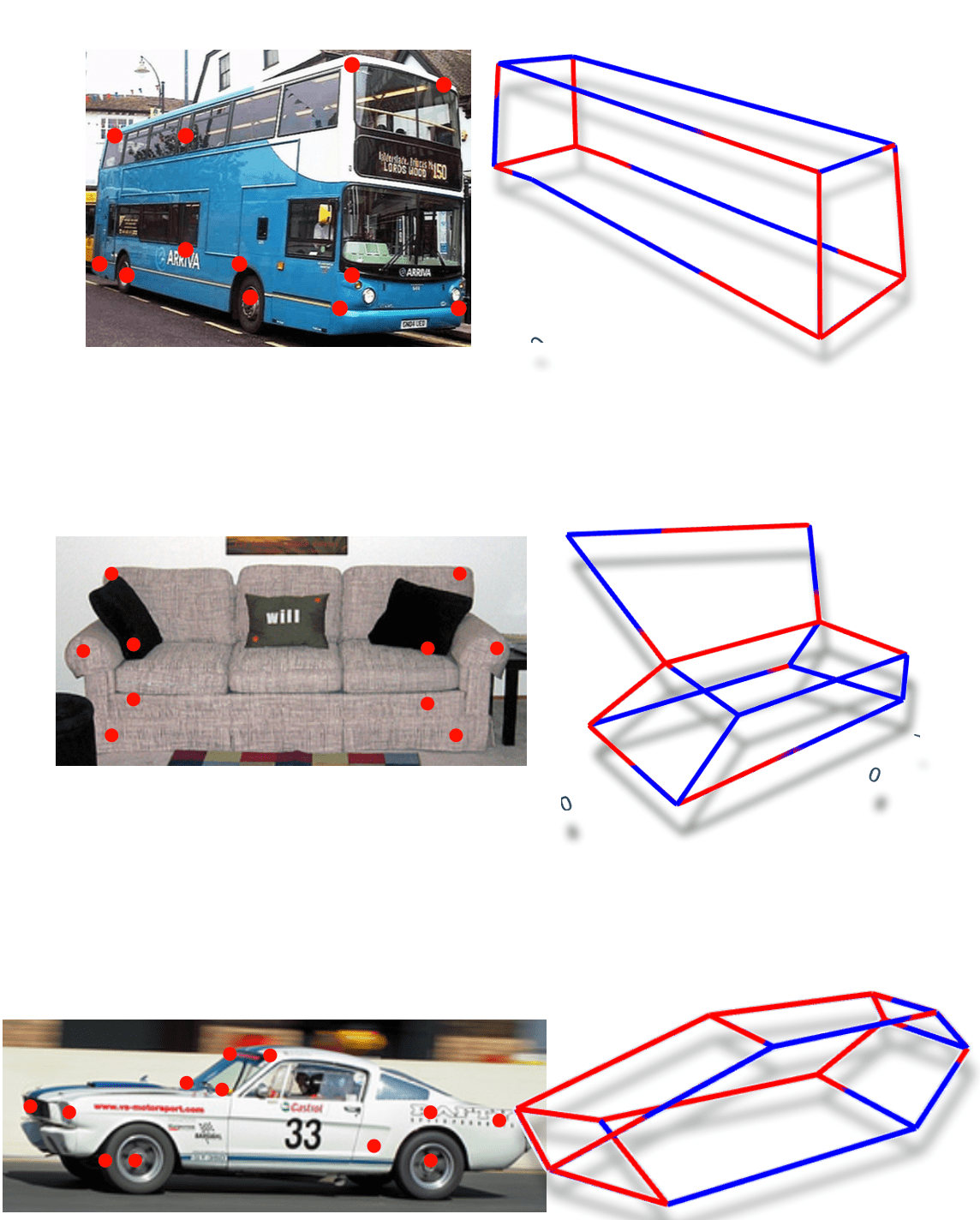


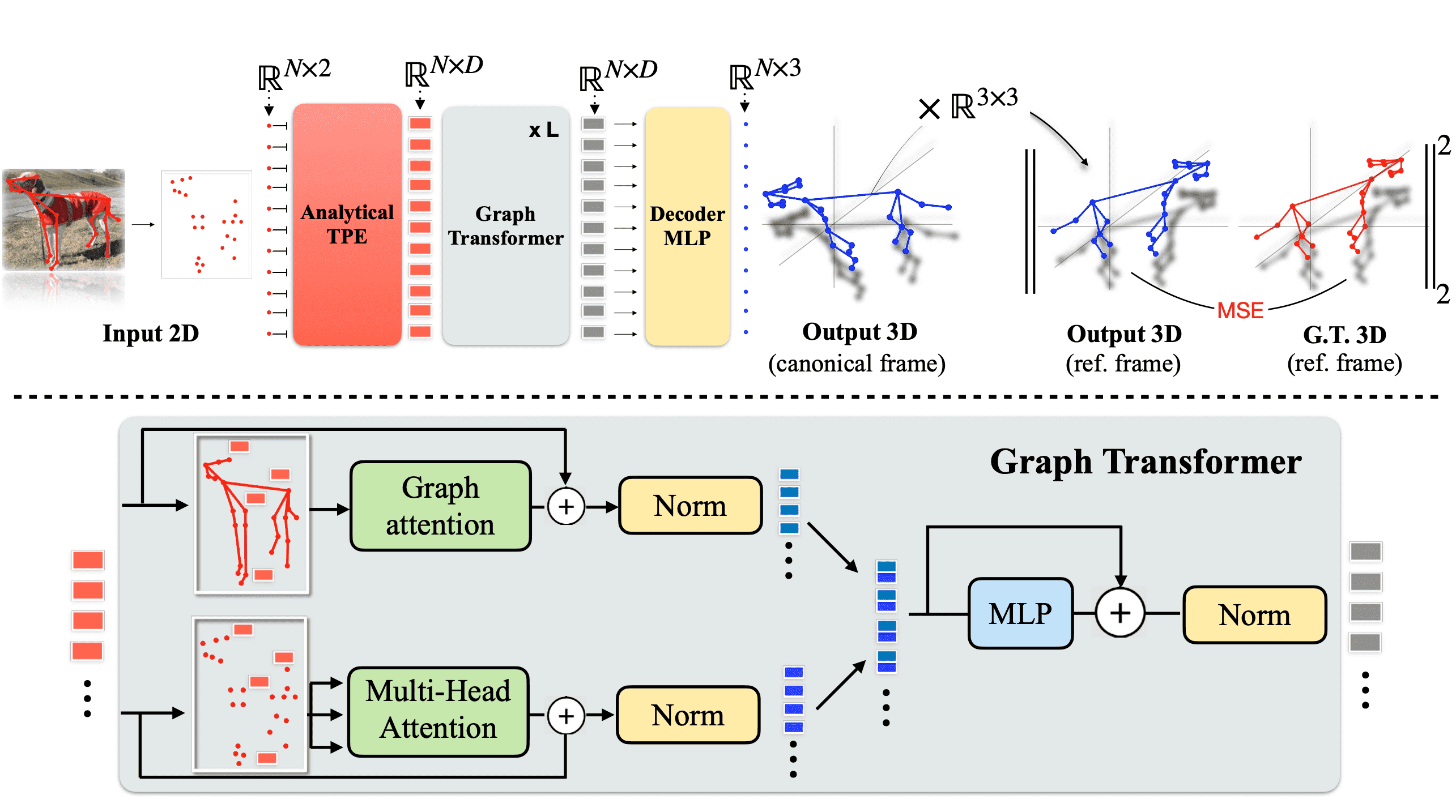
The 3D-LFM scales to multiple categories (30+ in our experiments), managing diverse landmark configurations through proposed architectural changes. See our paper for more details. Key: Red for ground truth, blue for predictions.